Pseudo-Statistics and Quantitative Charlatanism: The Effects of Reality on the Deflated Sharpe Ratio.
It is commonplace to observe that developing profitable investment strategies is difficult. Quant strategists are often driven to search over a large number of potential strategies, backtesting hundreds or thousands before selecting a potential candidate for trading. Given the relatively short history of available relevant data, quants often have to reason about their selected strategy using the same data used to select the strategy, a sure recipe for all kinds of biases and suboptimal decisions.
I have studied this problem quite a bit, and written about it elsewhere. In my research I have come across the "Deflated Sharpe Ratio" more than once, but had never taken it seriously. From reading the abstract of the original paper I thought it was just some kind of heuristic, instead of a statistical procedure. However, it has blossomed out into a small constellation of papers, with the intersected authorship consisting solely of Marcos López de Prado, Risk.net's 2021 Buy-Side Quant of the Year. As of writing this blog post the original paper has over 270 citations on google scholar, not all of them self-citations, with over 90 in the first half of 2026 alone, and a more extensive Wikipedia entry than the Sharpe ratio. The deflated Sharpe ratio has lodged itself in the firmament of quantitative finance, but how does it work and what does it do?
At a high level, the deflated Sharpe ratio procedure imagines that one observes historical performance of a large number of strategies. We can decompose historical performance as a sum of skill and luck. One then selects the strategy with the best in-sample performance, then performs some kind of inference on the skill of that strategy. In this case the skill can be quantified by the population Sharpe ratio (what I call the "signal-noise ratio"). One wants a strategy with high skill, since you cannot control luck: high skill leads to the best expected performance out-of-sample.
In our case the luck is the noise of the in-sample Sharpe ratio around the signal-noise ratio. The magnitude of this noise is controlled mostly by the length of the backtest period, and is approximately $1/T$ where $T$ days of backtested returns are observed.
The setup to the original DSR paper imagines that the distribution of sample Sharpe ratios is Gaussian with mean zero and variance $\sigma_s^2 + \sigma_l^2$, where $\sigma_s^2$ is the variance of the skill part, and $\sigma_l^2$ is the variance of the luck part, equal to around $1/T$. This is a simplified representation of the DSR procedure, ignoring some corrections for skew and kurtosis of returns, which will have no bearing on our analysis.
The DSR procedure is built on the "False Strategy Theorem" which gives a formula for the asymptotic expected value of the maximum of $n$ i.i.d. standard Gaussian random variables. We can think of this as just a function of $n$, call it $f(n)$. Now let $\hat{\zeta}_i$ be the observed Sharpe ratios of the $i$th backtest, and suppose we reorder them so that $\hat{\zeta}_n$ is the largest in-sample value. We are trying to perform inference on the skill of this strategy. The DSR is basically computed as $$ DSR = \Phi\left(\frac{\hat{\zeta}_n - \sqrt{\sigma_s^2 + \sigma_l^2}f(n)}{\sigma_l}\right). $$ That is, we subtract the (approximate) expected value of the maximum of skill plus luck, divide by the spread of the luck, then feed the result through the CDF of the normal distribution.
In the original 2014 paper, the authors allude to the DSR being used as a statistical procedure. They give a number of example computations, and talk about rejecting a null hypothesis based on whether the computed DSR exceeds 0.95 or not. (A larger value of the DSR apparent casts doubt on the null hypothesis.) The 2018 paper by López de Prado and Lewis defines the DSR as "the probability that the true SR exceeds a user-defined benchmark level $SR^*$, where that level is adjusted to reflect the multiplicity of trials." Ignoring that frequentists do not assign probabilities to underlying parameters, the intention is fairly clear that DSR is to be interpreted as a p-value.
Wait, What?
I had a number of concerns after reading this paper. Among them:
-
The assumption that sample Sharpe ratios are normally distributed seems indefensible in practice, and is likely load-bearing. There are two issues here. Even if one assumes that returns are well behaved (independent Gaussian, say), the Sharpe ratio is fat-tailed. The distributional shape of skill will not change this. Because the "False Strategy Theorem" is based on asymptotics of the normal distribution, and because we are looking at extremal values, the fat-tailedness of the sample Sharpes is likely to break the expected value used in the DSR computation. The expectation subtracted in the numerator of DSR is probably wrong.
The other issue with this assumption is that skill is unlikely to be normally distributed, which is pretty much required if skill plus luck is normally distributed. Quants tend to test small variations on a number of different heterogenous strategies. Normality seems like a very poor model for how skill is distributed. The authors of the original paper ignore this issue, but it seems like it is addressed in the followup paper by López de Prado and Lewis. Needless to say the followup paper requires some results from the original paper that are demonstrably wrong.
-
The definition of the DSR is quite odd. The numerator $\hat{\zeta}_n - \sqrt{\sigma_s^2 + \sigma_l^2}f(n)$ should be approximately zero mean if the expected value of the sample Sharpe ratios is zero, but larger otherwise. How much larger is hard to say, but it does not seem that it should depend only on $\sigma_l$, which is what we divide it by. In fact, it seems that the intent is to measure how many "luck units" away we are from what we suspect should be zero. The problem is that the maximal sample Sharpe $\hat{\zeta}_n$ has both skill and luck in it, and we cannot just pretend that we maximized over skill and then had luck-sized noise on top of that.
-
This also raises the issue of what null exactly is putatively being tested here. The authors do not state this clearly, in either the original 2014 paper or the 2018 followup. There are a few obvious choices: the unconditional null, which is that the expected value of all the sample Sharpe ratios is zero; and the conditional null which is that the skill of the selected strategy is zero, symbolically $\zeta_n = 0$, where $n$ is the index of the strategy with the largest observed sample Sharpe ratio. (We do not know, or exactly care, if $\zeta_n$ is the largest of the skill values.) Lastly there is a conditional familywise null which is that the skill of all strategies is zero (or non-positive), symbolically $\zeta_i = 0$ for all $i$. We suspect the authors intended to test the conditional null, as the other two nulls can be tested with standard MHT corrections like Bonferroni. The two other nulls also do not seem super useful, since they are not strictly about the skill of the selected strategy.
-
You might be wondering how the authors proved that the DSR is uniform under the null hypothesis if they did not state the null hypothesis. I regret to inform there is no proof of this statement. Instead, the efficacy of DSR for controlling type I errors rests on the reputation of the authors and the editors of the Journal of Portfolio Management.
Disproving Uniformity of the DSR
The fact that I could not immediately grasp the justification for the DSR is not real cause for concern. After all, there are many, many things I do not understand. However the absence of a proof, or even a hand-wave justification, is troubling from my point of view. The authors and editors did not seem to think a proof was necessary.
I now believe that no proof was offered because there is no proof, as the statement is clearly false. Consider the simplified case where there is no spread in skill, $\sigma_s=0$. In this case all strategies have the same skill which we assume to be zero. (Note that if this were true there would be no reason to select among the strategies, but this is the limiting case where spread of luck is much larger than spread of skill.) The three nulls happen to coincide here, so it does not matter which one the original authors intended. Suppose that $\sigma_l=1$ by choice of units, so that DSR is defined as $\Phi\left(\hat{\zeta}_n - f(n)\right)$. For large $n$ the maximum of $n$ i.i.d. Gaussians tends to a Gumbel distribution. This is simply not normally distributed, and the DSR should not be uniform under the null.
We can simulate this very easily. We simulate $n$ independent Gaussians, select the maximal one, subtract the magical value, take the CDF, and get something that should be uniform if we believe the DSR is a p-value. We run this simulation $10^5$ times and plot the empirical CDF of these putative p-values. If the DSR were uniform this would be a straight line segment from $(0,0)$ to $(1,1)$. It clearly is not. Note that we are simulating $n=50000$ strategies here, so the problem is not the asymptotics: these are the asymptotics. In fact, using larger $n$ does not improve the situation. This is evident from other testing we have done and is obvious from the asymptotics, since the variance of the maximum of $n$ Gaussians is shrinking in $n$. This even figures into the 2014 paper of this constellation, but apparently did not occur to authors of the DSR paper.
exp_max_sr <- function(N) {
mascher <- 0.5772156649
(1 - mascher) * qnorm((1/N), lower.tail=FALSE) + mascher * qnorm(exp(-1)/N, lower.tail=FALSE)
}
nstrat <- 50000
limval <- exp_max_sr(nstrat)
set.seed(1234)
simvals <- replicate(1e5,{
srs <- rnorm(nstrat, mean=0, sd=1)
dsr <- pnorm(max(srs) - limval)
})
library(tibble)
library(dplyr)
library(ggplot2)
ph <- tibble(sample=simvals) %>%
ggplot(aes(x=sample)) +
stat_ecdf() +
labs(title='Empirical CDF of DSR Values',x='DSR',y='Empirical CDF',caption=paste0('Over 100K simulations of ',nstrat,' tested strategies, with no skill spread.'))
print(ph)
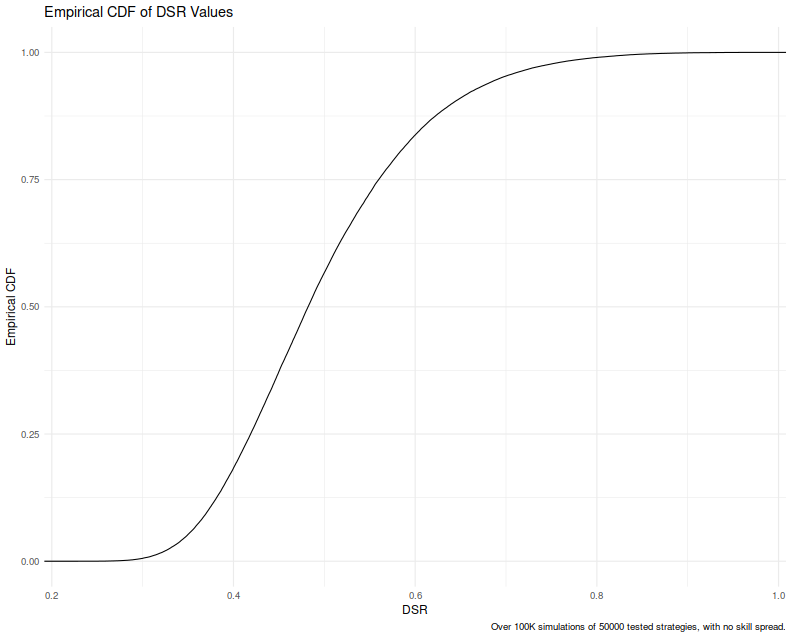
Note that conservatively these simulations require 20 lines of code to execute and plot, and took 15 minutes to write and execute. That the original authors never bothered to check this is mind-boggling. The first DSR paper does contain simulations, but only to check how the mean value of $\hat{\zeta}_n$ compares to the asymptotic value as one varies $n$. While this is an interesting question, it rather misses the mark. The problem with DSR, as it turns out, is not that $f(n)$ is inaccurate for small $n$; rather the issue is that the DSR does not make any sense.
As one can see from the plot above, in some situations we should expect that the probability that DSR exceeds $1-\alpha$ will often be much smaller than $\alpha$. To illustrate the issue, we simulate using numbers from the original DSR paper. As in the original paper, we assume 250 trading days per year, let $\sigma_s^2 + \sigma_l^2 = 0.5$ in "annualized units", let $T = 1250$ days (5 years at this cadence), assume returns are normally distributed, and consider either $n = 88$ or $n = 89$. First we write a DSR function and confirm that if $\hat{\zeta}_n=2.5$ in annualized units that this DSR function spits out 0.9505 when $n = 88$, as in the original paper.
exp_max_sr <- function(N) {
mascher <- 0.5772156649
(1 - mascher) * qnorm((1/N), lower.tail=FALSE) + mascher * qnorm(exp(-1)/N, lower.tail=FALSE)
}
dsr <- function(sr, T, N, Vsrs, Esrs=0, gamma3=0, gamma4=3, ...) {
sr0 <- Esrs + sqrt(Vsrs) * exp_max_sr(N)
serr <- sqrt((1 - gamma3 * sr + (gamma4 - 1)/4*sr**2) / (T-1))
pnorm((sr - sr0) / serr, ...)
}
dpy <- 250
zeta_n <- 2.5
T <- 1250
n <- 88
sigmasq_tot <- 0.5
# compute and print
print(dsr(zeta_n / sqrt(dpy), T=T, N=n, Vsrs=sigmasq_tot / dpy))
[1] 0.950491
print(dsr(zeta_n / sqrt(dpy), T=T, N=n+1, Vsrs=sigmasq_tot / dpy))
[1] 0.949839
I indeed get 0.9505, as in the original paper. Moreover, when $n=89$, the DSR falls slightly under 0.95 and, if we are to believe the narrative of the original paper, a conscientious investor would fail to reject the null and not invest in the strategy. Our code matches the code in the paper by visual inspection and spits out the same values, and we can proceed.
Now we will perform a number of simulations with these values of $T, n$ and noise. In each of them we will first draw from normally distributed skill, then add some amount of luck to that. We will select the "strategy" with the highest combined skill plus luck. We will compute the DSR on the simulated Sharpe of this strategy. We then get the actual skill and the DSR value. This will allow us to test the conditional null by focusing on cases where the actual skill is either less than zero, or very close to it.
Below we perform the simulations under these values of $T, n, \sigma^2_s$.
#' perform a number of simulations of normal skill plus normal luck,
#' compute the DSR on the results, return the SNR of the strategy
#' selected for having maximal sharpe, along with that maximal sharpe and the DSR statistic.
sim_machine <- function(T, n, sigmasq_tot, nsims=100000, dpy=250) {
require(tibble,quietly=TRUE)
sigma_luck_day <- sqrt(1/T)
sigma_tot_day <- sqrt(sigmasq_tot / dpy)
sigma_skill_day <- sqrt(sigma_tot_day^2 - sigma_luck_day^2)
simvals <- replicate(nsims, {
skills <- rnorm(n, mean=0, sd=sigma_skill_day)
srs <- rnorm(length(skills), mean=skills, sd=sigma_luck_day)
maxsr <- max(srs)
nidx <- order(srs, decreasing=TRUE)[1]
selskill <- skills[nidx]
dsrv <- dsr(maxsr, T, N=n, Vsrs=sigma_tot_day^2)
c(skill=selskill, dsr=dsrv, maxsr=maxsr)
})
as_tibble(t(simvals))
}
T <- 1250
n <- 88
sigmasq_tot <- 0.5
set.seed(1234)
results <- sim_machine(T=T, n=n, sigmasq_tot=sigmasq_tot, nsims=1e6)
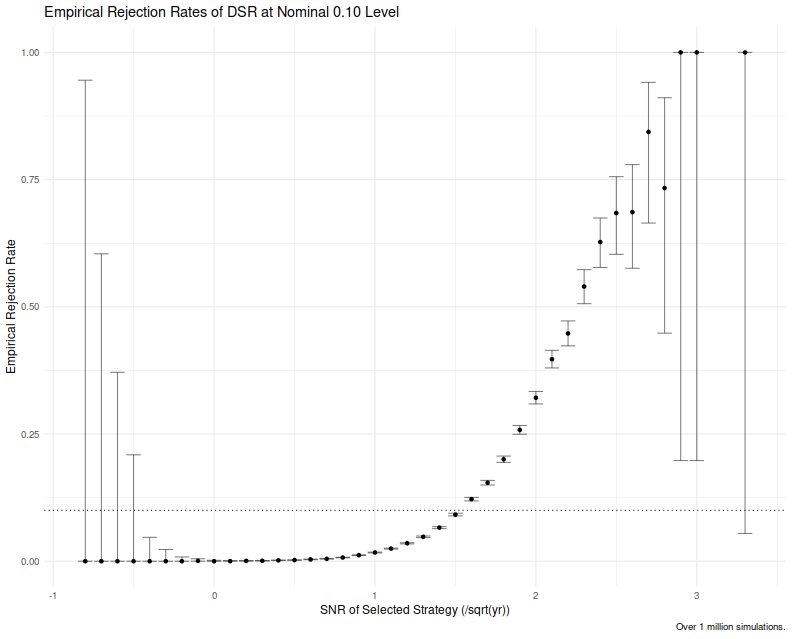
Now we compute the empirical rejection rates. To avoid "bottoming out", we pretend we are interested in a type I rate of 0.10, so our decision threshold is to reject when $DSR > 0.9$. Here we tabulate the empirical rejection proportion for the entire simulation, which is under the unconditional null, as well as for those small number (less than 1%!) of cases where the skill of the selected strategy is non-positive, which is the conditional null. We compute 95% confidence intervals on the rejection rate based on our simulations, and tabulate these below.
We see only one rejection at the nominal 0.10 level under the conditional null, which we observe over 3000 times in 1 million simulations. For the conditional null the actual rejection rate is around 100 times smaller than the nominal 0.10 rate promised by the DSR. Under the unconditional null the empirical rejection rate is more like 4%, not the nominal 10%. We note, however that under this unconditional null there are many cases where the skill of the selected strategy is quite large, larger than 1.5 in annualized units. And yet the rejection rate is still small.
#' estimate the rejection rates along with confidence intervals on same
#' assumes the skill has already been grouped into skill_group variable.
compute_rejrates <- function(results, conf.level=0.95, dsr_thresh=0.95) {
results %>%
group_by(skill_group) %>%
summarize(Rejections=sum(dsr > dsr_thresh), Total=n()) %>%
ungroup() %>%
mutate(`Rejection Proportion`=Rejections/Total) %>%
mutate(conf.lo=mapply(function(x, n) {prop.test(x, n, conf.level=conf.level)$conf.int[1]}, Rejections, Total)) %>%
mutate(conf.hi=mapply(function(x, n) {prop.test(x, n, conf.level=conf.level)$conf.int[2]}, Rejections, Total))
}
library(knitr)
bind_rows(results %>%
mutate(skill_group="unconditional null"),
results %>%
dplyr::filter(skill < 0) %>%
mutate(skill_group="conditional null")) %>%
compute_rejrates(dsr_thresh=0.9) %>%
rename(`Group`=skill_group) %>%
knitr::kable(caption='Empirical rejection rates for simulations using 0.9 DSR threshold.', format='markdown', digits=3)
Table: Empirical rejection rates for simulations using 0.9 DSR threshold.
| Group | Rejections | Total | Rejection Proportion | conf.lo | conf.hi |
|---|---|---|---|---|---|
| conditional null | 1 | 3361 | 0.000 | 0.000 | 0.002 |
| unconditional null | 41627 | 1000000 | 0.042 | 0.041 | 0.042 |
To get a feel for how the DSR rejects at the nominal 0.10 level, we group cases by their underlying skill, rounding to the nearest 0.1 in annualized units. We compute the empirical rejection rates of the DSR along with (pointwise, not familywise) 95% confidence intervals, which we plot here. We see that the empirical rejection rate does not exceed the nominal level until the skill is around 1.5 in annualized units. The DSR has apparently very low power when the skill is less than 2 in annualized units.
rejrates <- results %>%
mutate(skill_group=round(sqrt(250)*skill, 1)) %>%
compute_rejrates(dsr_thresh=0.90)
ph <- rejrates %>%
ggplot(aes(skill_group, `Rejection Proportion`, ymin=conf.lo, ymax=conf.hi)) +
geom_point() +
geom_hline(yintercept=0.1,linetype="dotted") +
geom_errorbar(alpha=0.5) +
labs(x='SNR of Selected Strategy (/sqrt(yr))',
y='Empirical Rejection Rate',
title='Empirical Rejection Rates of DSR at Nominal 0.10 Level',
caption='Over 1 million simulations.')
print(ph)
Steelmanning the DSR
Note that in our simulations we found that the type I rate of DSR seems to be quite smaller than the nominal rate. Toying with the parameters, we have not found cases where the empirical rejection rate exceeds the nominal rate, which is to say we suspect that the DSR is uniformly conservative. It is not uncommon in statistical practice to employ a statistic that depends on some unobserved nuisance parameter. In that case one usually identifies a least favorable configuration, which is some value of the unobserved nuisance parameter at which the type I rate is maximized under the null, then calibrate the procedure to that case. The guarantees of the procedure then become an upper bound on the type I rate. Could this rescue the DSR?
First note that the original authors do not make this claim. López de Prado and Lewis do not make that claim either, instead they use DSR as if it were uniform under the null.
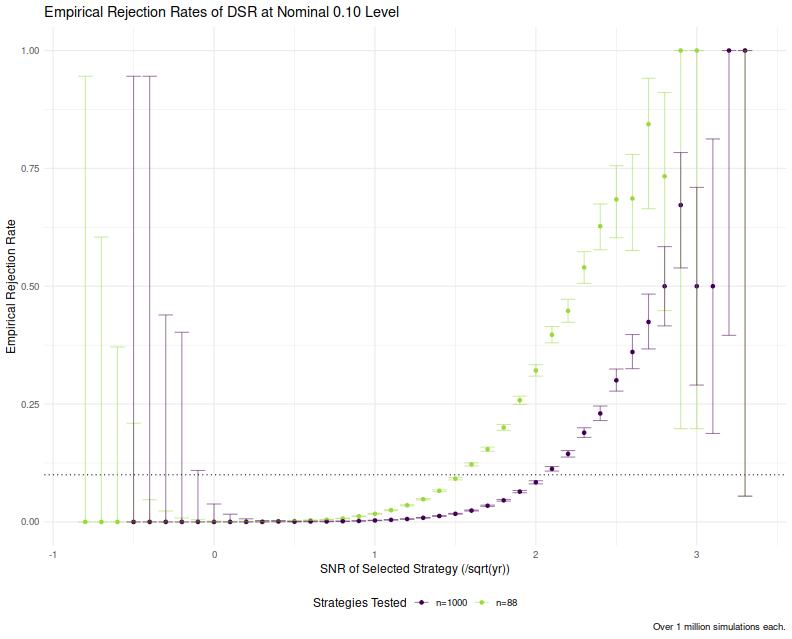
Second, it is easy to establish that the distribution of the DSR under the null depends not on an unobserved nuisance parameter, but on the observed value of $n$. The DSR simply has more spread for smaller $n$. This means that for a fixed value of the skill of the selected strategy, the DSR is more likely to reject for small $n$ than for large $n$. We confirm this experimentally below by repeating the above experiments but setting $n=1000$. We plot the conditional empirical rejection rates at the nominal 0.10 level for both sets of simulations and see a much higher rejection rate for the case where $n=88$. Presumably the "least favorable configuration", then, would be $n=1$, where we do not trust $f(n)$ to be any good. However, this variable rejection rate is going to be a serious problem if one attempts to use the DSR result for different normally distributed clusters of skill, as do López de Prado and Lewis. Their proposed solution is built on very shaky foundations, and I would not trust it at all: it will preferentially surface small clusters over large clusters for no good reason.
results2 <- sim_machine(T=T, n=1000, sigmasq_tot=sigmasq_tot, nsims=1e6)
rejrates2 <- results2 %>%
mutate(skill_group=round(sqrt(250)*skill, 1)) %>%
compute_rejrates(dsr_thresh=0.90)
ph <- bind_rows(rejrates %>% mutate(n=88),
rejrates2 %>% mutate(n=1000)) %>%
mutate(experiment=paste0("n=",n)) %>%
ggplot(aes(skill_group, `Rejection Proportion`, ymin=conf.lo, ymax=conf.hi,
color=experiment, group=experiment)) +
geom_point() +
geom_hline(yintercept=0.1,linetype="dotted") +
geom_errorbar(alpha=0.5) +
labs(x='SNR of Selected Strategy (/sqrt(yr))',
y='Empirical Rejection Rate',
title='Empirical Rejection Rates of DSR at Nominal 0.10 Level',
color='Strategies Tested',
caption='Over 1 million simulations each.')
print(ph)
In one last-ditch effort to steelman the DSR, perhaps we should just assume that one always uses it for fixed values of $n$ and $T$, and then performs simulations like the ones I have done here to get the proper threshold value of DSR to reject at a given type I rate. There are so many things wrong with this approach, however:
- It requires the user to run a bunch of simulations to fix a broken statistic? Is it not the responsibility of the original authors to do this?
- If you fix the $n$ and $T$, then the DSR is monotonic in $\hat{\zeta}_n$. So if you are going to run these simulations, why waste your time with computing $f(n)$ and the normal CDF? Instead just find threshold values for $\hat{\zeta}_n$ under the conditional null you seek to test, you get the same results. Note that this is just the in-sample Sharpe ratio that these authors have spent five plus papers telling us was biased and useless.
No, there is no rescuing the DSR. Stop using it, it makes no sense, and it does not do what it was advertised to do.
Is DSR a Fraud?
Bailey et al ask a similar question in their paper on "backtest overfitting". A fraud is an intentional act of deception or a misrepresentation of facts to gain an unfair advantage. I will stress however, there is no evidence whatsoever of intentional deception here. The DSR is not a fraud, but it is a misrepresentation of the truth. In cases like these I employ Hanlon's razor: "Never attribute to malice that which is adequately explained by ignorance". Writing and publishing the DSR paper(s) without spending even five minutes thinking about whether it is true, or 30 minutes testing it, is in my opinion outright statistical malpractice. The paper should be retracted, and I will present my case to JPM, though I doubt it will be.
References
- Bailey, David H. and López de Prado, Marcos. 2014. The Deflated Sharpe Ratio: Correcting for Selection Bias, Backtest Overfitting and Non-Normality Journal of Portfolio Management, 40(5): 94-107. (40th Anniversary Special Issue), DOI: 10.2139/ssrn.2460551
- López de Prado, Marcos and Lewis, Michael J. 2018. Detection of False Investment Strategies Using Unsupervised Learning Methods Quantitative Finance, 19(9): 1555-1565. DOI: 10.2139/ssrn.3167017 DOI: 10.1080/14697688.2019.1622311
- López de Prado, Marcos and Bailey, David H. 2021. The False Strategy Theorem: A Financial Application of Experimental Mathematics American Mathematical Monthly, 128(9): 806-817. DOI: 10.1080/00029890.2021.1965068
- Bailey, David H. and Borwein, Jonathan and Borwein, Jonathan and López de Prado, Marcos and Zhu, Qiji Jim. 2014. Pseudo-Mathematics and Financial Charlatanism: The Effects of Backtest Overfitting on Out-of-Sample Performance Notices of the American Mathematical Society, 61(5): 458-471. DOI: 10.2139/ssrn.2308659
Appendix: What Should You Do Instead?
This blogpost is not about me, but I have done research on this problem.
I would be remiss if I did not point readers to my preprint,
which is ostensibly about a procedure which does maintain nominal coverage under the conditional null.
The paper snowballed however and also contains several tests for the unconditional null,
with some analysis of the false discovery rate, etc.
The tests are available in the SharpeR R package as sr_conditional_test and sr_max_test.
By no means do I consider the topic closed, however.
I think the conditional procedure can be improved to have higher power, and am slowly researching and developing a fix.